Building your very own blog using Phoenix Liveview and Markdown
Helping others, fun, learning new skills - these are few of many reasons that draw people to blogging. Combine this with the accessibility provided by the web, and it’s easy to understand why it has become one of the most popular forms of publication. As it often happens, with popularity comes community, blogging is no different here. Currently, there’s no shortage of platforms and tools that simplify the process for those who are less tech-savvy. Nonetheless, building your own foundation for any activity can be rewarding and valuable. Today we’ll create an app that reads and parses markdown files to html using simple tools like earmark and tailwindcss-typography.
This article assumes that the reader has a basic understanding of routing and Liveview callbacks in Phoenix Liveview.
Contents:
Structure
We’ll begin by spinning up a new Phoenix project and calling it ‘my_blog’, but before we start coding, we should consider what our markdown file structure should look like. A typical blog post could be separated into two parts, metadata and content. The former holds information like title or tags, the latter represents the actual subject matter. A quick google search reveals that YAML-like metadata is one of the most widely accepted formats, so we’ll go with that. The content will be written in plain markdown and always start with title in #(h1 tag). If you have never used markdown or need a reminder, here’s a markdown guide that will get you sorted out.
Let’s take a moment to think about what the metadata portion of the file should include. Metadata entries will be used to represent information about a post, so we likely could use fields for holding author’s name, title, a short description of the article, publication date, tags for filtering, keywords for SEO, an image URL or path and an ID to help implement comments and likes. If we go ahead and put it together, we would end up with something akin to this:
---
id: efd73b5f-c2ca-4e3c-8cdd-0cd954ae0066
title: Easy Phoenix blogging
excerpt: It is super easy and simple to start blogging with Phoenix Liveview.
author: John Doe
keywords: build liveview blog, how to start blogging with phoenix liveview
tags: blog, markdown, md, phoenix, liveview
published: 2025-01-01
bg: /path/to/image.png
---
# Easy Phoenix blogging
## Easy and simple blogging with Phoenix Liveview.
Paragraph with content
Notes
- To avoid problems in the future let’s adopt the ISO 8601 date format(YYYY-MM-DD).
-
To generate an ID, we can use Phoenix’s Ecto.UUID.generate function. Just type
Ecto.UUID.generatein IEx to get the ID and copy it over.
Reading Markdown files
Before we read anything we need a file. Let’s create a folder to hold our markdown. In the root of our project create content folder, inside it we’ll nest two more - md and articles (content/md/articles). Regardless of whether we’ll keep files of different types here or not, it is a good practice to organise folders. Next, create a markdown file and paste our example from Structure section. Name it however you want, as we won’t use its name to identify it, remember though, that you have to set the file’s extension to .md.
Utils - Functions that read and extract various parts of an article
Ok, we have our file, time to read it and extract metadata entries we talked about earlier. We’re going to build a module called utils.ex, put it in lib/my_blog/utils/. The get_md_paths_and_titles/1 will be run in Title : path cache that we’ll build in a moment. The rest of the functions in this module are dealing with metadata using regex.
defmodule MyBlog.Utils.Utils do
@moduledoc """
Module holding the utility functions needed by the application.
"""
alias MyBlog.Utils.MarkdownValidator
@doc """
Reads markdown files from `content/md/articles/` directory, validates them and returns their paths with titles.
"""
def get_md_paths_and_titles(:articles) do
Path.wildcard("content/md/articles/**/*.md")
|> Enum.map(fn x -> MarkdownValidator.validate_md_file(x) end)
|> Enum.map(fn y-> {elem(y, 0), extract_title(elem(y, 1))} end)
end
@doc """
Reads contents of a markdown file.
"""
def read_md(path) when is_binary(path) do
file = File.read(path)
case file do
{:error, _msg} ->
{:error, "Could not read file"}
{:ok, data}->
data
end
end
@doc """
This function takes path to and markdown file itself. Then runs a regex expression against the file that extracts the metadata from between the hyphens("---") and filters out all non-word characters. It prepares and converts metadata key-value pairs into a map.
"""
def extract_metadata(md) do
indices = Regex.run(~r/(?<=---)[\s\S]*?(?=---)/, md, return: :index)
unfiltered_metadata =
String.split(
String.slice(md, (elem(hd(indices), 0))..(elem(hd(indices), 1) + 1)),
~r/[\n]/
)
filtered_meta = Enum.filter(unfiltered_metadata, fn x -> String.match?(x, ~r/\w+/) end)
key_value_pairs = Enum.map(filtered_meta, fn f -> String.split(f, ~r/:/) end)
map = Enum.into(key_value_pairs, %{}, fn [a, b] -> {String.trim(a), String.trim(b)} end)
if !Map.has_key?(map, "tags") do
raise "Articles metadata lacks tags property"
end
Map.replace(map, "tags", Enum.map(String.split(map["tags"], ","), fn x -> String.trim(x) end))
end
@doc """
Runs a regex against a markdown file and returns everything after the first "#"(h1) tag.
"""
def extract_article(md) do
article = Regex.run(~r/(?=#).[\s\S]*/, md)
case article do
nil ->
{:error, "Article has no content"}
_ ->
article
end
end
@doc """
Extracts an id from an article.
"""
def extract_id(md) do
hd(Regex.run(~r/(?<=id: ).*/, md))
end
@doc """
Extracts a published entry from an article.
"""
def extract_published(md) do
hd(Regex.run(~r/(?<=published: ).*/, md))
end
@doc """
Extracts a title form an article.
"""
def extract_title(md) do
hd(Regex.run(~r/(?<=title: ).*/, md))
end
@doc """
Takes a list of maps and converts the strings under the 'published' key into a datetime.
"""
def convert_map_string_to_date(map) when is_list(map) do
map
|> Enum.map(fn x -> Map.replace(x, "published", Date.from_iso8601!(x["published"])) end)
end
end
Validation
Since human input is prone to error, some kind of file validation system wouldn’t hurt. We’re about to implement a simple module that does just that. In lib/my_blog/utils/ create markdown_validator.ex, it will contain a function that runs checks on a file specified by a path.
defmodule MyBlog.Utils.MarkdownValidator do
alias MyBlog.Utils.Utils
@moduledoc """
This module is responsible for validating markdown files.
"""
@md_keys [ "id", "title", "excerpt", "author", "keywords", "tags", "published", "bg"]
@doc """
Runs a series of checks to validate file's existence, extension, metadata and content. Raises if validation fails, returns `path` and file content when complete.
"""
def validate_md_file(path) do
path
|> raise_file_non_existent
|> raise_file_wrong_ext
|> raise_file_no_meta
|> raise_file_no_content
|> raise_incorrect_date_format
end
defp raise_file_non_existent(path) do
{status, data} = File.read(path)
if status == :error do
raise :file.format_error(data)
else
{path, data}
end
end
defp raise_file_wrong_ext({path, data}) do
if Path.extname(path) != ".md" do
raise "File located at #{path} is not a markdown file."
else
{path, data}
end
end
defp raise_file_no_meta({path, data}) do
metadata = Utils.extract_metadata(data)
missing = Enum.filter(@md_keys, fn k -> !Map.has_key?(metadata, k) end)
if length(missing) > 0, do: raise "File's metadata is missing the following properties: #{Enum.map(Enum.with_index(missing), fn {x, index} -> if index == length(missing)-1, do: x<>".", else: x<>", " end)}"
{path, data}
end
defp raise_file_no_content({path, data}) do
content = Utils.extract_article(data)
case content do
{:error, _msg} ->
raise "File located at #{path} must have content part that starts with a h1 heading(#)."
_->
{path, data}
end
end
defp raise_incorrect_date_format({path, data}) do
metadata = Utils.extract_metadata(data)
published = Map.fetch!(metadata, "published")
case Date.from_iso8601(published) do
{:ok, _} ->
{path, data}
_->
raise "Incorrect value of field 'published' specified, use format: 2000-01-01"
end
end
end
Path : title cache
As we want to find our markdown files by title, but can’t read them without a path, we have to think of some kind of mechanism that will allow us to store posts’ file paths and titles as key / value pairs. We could have a json file that keeps paths and titles of our files somewhere in the project, but updating it every time we post would be a chore. Why not utilize the tools at our disposal and implement a simple GenServer module that will read and keep the paths of our files in an :ets table. Create a new file article_tracker.ex in our lib/my_blog folder. We don’t really need anything fancy, just a start_link/3 function along with init/1 and a few of handle_call/3 callbacks. The whole idea is to start the GenServer in a Supervisor tree so it becomes online when the app is launched, at the start it will read the articles in the path we specified, extract the titles and store them along with paths as tuples. In init/1 we call our Utils module to grab paths and titles. We also need to initialize a new :ets table and save them in it.
defmodule MyBlog.ArticleTracker do
use GenServer
alias MyBlog.Utils.Utils
@moduledoc """
A GenServer module responsible for keeping track of article titles and file paths.
"""
def start_link(_) do
GenServer.start_link(__MODULE__, [], name: ArticleTracker)
end
def init(_) do
:ets.new(:articles_data, [:protected, :set, :named_table])
articles = Utils.get_md_paths_and_titles(:articles)
Enum.map(articles, fn a -> :ets.insert(:articles_data, a) end)
IO.puts("\nStarting ArticleTracker\n")
{:ok, %{:article => :articles_data}}
end
end
Our next step is to add the ArticleTracker to the app’s Supervisor tree. Open application.ex in lib/my_app directory, find the start/2 function and expand it’s children list with a new entry MyBlog.ArticleTracker. If we start our Phoenix server with iex -S mix phx.server, we should see a message in our terminal: “Starting ArticleTracker”. That means our GenServer is up and running. It’s high time we added some logic to handle our data.:
# # # # callers # # # #
def save_article(title, path) do
GenServer.call(ArticleTracker, {:save_article, {path, title}})
end
def get_article_path(title) do
GenServer.call(ArticleTracker, {:read_article, {title}})
end
def get_all_article_paths() do
GenServer.call(ArticleTracker, {:all_article_paths})
end
# # # # handlers # # # #
def handle_call({:save_article, {path, title}}, _from, state) do
result = :ets.insert(state.article, {path, title})
{:reply, result, state}
end
def handle_call({:read_article, {title}}, _from, state) do
result = :ets.match(state.article, {:"$1", title})
case result do
[] ->
{:reply, :not_found, state}
_ ->
{:reply, hd(hd(result)), state}
end
end
def handle_call({:all_article_paths}, _from, state) do
result = :ets.match(state.article, {:"$1", :_})
case result do
[] ->
{:reply, :empty, state}
_ ->
{:reply, List.flatten(result), state}
end
end
Stop and launch the phoenix server once again with iex -S mix phx.server. In iex type MyBlog.ArticleTracker.get_all_article_paths, the shell should return the file path of our post:
[content/md/articles/filename.md"].
Wrapping it up
In our lib/my_blog/ directory - often used to store contexts - create a new file called blog.ex, it will hold all blog related logic. This module will deal with all the requests made by liveview files, e.g. fetching content body of an article.
defmodule MyBlog.Blog do
alias MyBlog.ArticleTracker
alias MyBlog.Utils.Utils
@doc """
Takes an article's title and returns the content.
"""
def get_article_by_title(title) do
case ArticleTracker.get_article_path(title) do
:not_found ->
{:error, "No article titled `#{title}` found"}
article_path ->
hd(Utils.read_md(article_path) |> Utils.extract_article())
end
end
@doc """
Returns article's metadata.
"""
def get_article_metadata(title) do
path = ArticleTracker.get_article_path(title)
file = Utils.read_md(path)
Utils.extract_metadata(file)
end
@doc """
Returns the metadata of all of the articles.
"""
def get_articles_metadata() do
case ArticleTracker.get_all_article_paths() do
:empty ->
:empty
paths ->
metadata =
Enum.map(paths, fn p -> Utils.read_md(p) end)
|> Enum.map(fn p -> Utils.extract_metadata(p) end)
|> Utils.convert_map_string_to_date()
|> Enum.sort(fn am1, am2 -> Date.compare(am1["published"], am2["published"]) != :lt end)
metadata
end
end
endWith that in place, we can focus on creating our liveview pages.
Rendering
In order to transform markdown to html we need to use a parser. Thankfully, Earmark got our back. Let’s go ahead and install it by adding {:earmark, "~> 1.4"} to the project’s deps function located in mix.exs file and running mix deps.get in the terminal. With html parser in place, it would be great to have some kind of automated styling. As it happens, tailwindcss-typography provides just this. Open up tailwind.config.js in assets directory and add require('@tailwindcss/typography') in plugins.
Implementing liveviews to display our post’s metadata and the post itself
After this initial setup, we’re ready to begin creating the pages. This brings a need for a new folder live, put it in lib/my_app_web. In there, make two new liveview files called blog_live.ex and article_live.ex, define the modules and callbacks. When a user navigates to the /blog route, we’ll fetch the paths from ArticleTracker and extract metadata from the files they’re pointing to. Only thing left is to render the metadata in a list and create a link to the article with its tile as a path.
defmodule MyBlogWeb.BlogLive do
use MyBlogWeb, :live_view
alias MyBlog.Blog
def mount(_params, _session, socket) do
metadata = Blog.get_articles_metadata()
{:ok, socket|> assign(:metadata, metadata)}
end
def render(assigns) do
~H"""
<div class="flex gap-2 flex-col p-8">
<%= for meta <- @metadata do %>
<.link navigate={"/blog/#{meta["title"]}"} class="flex text-sm flex-col p-2 hover:-translate-y-1 transition rounded-md gap-2 bg-black/70 hover:bg-sky-700 text-white">
<span class="font-bold text-base"><%= meta["title"] %></span>
<span class="font-semibold"><%= meta["author"] %></span>
<span><%= meta["published"] %></span>
</.link>
<% end %>
</div>
"""
end
end
In article_live.ex we grab the title from the params. Adding the prose class to the parent element of the article will trigger typography plugin. We can customize the styles by providing elements modifiers, e.g.: prose-h1:text-sky-700.
defmodule MyBlogWeb.ArticleLive do
use MyBlogWeb, :live_view
alias MyBlog.Blog
def mount(params, _session, socket) do
%{"title" => title} = params
article = Blog.get_article_by_title(title)
{:ok, socket|> assign(:article, article)}
end
def render(assigns) do
~H"""
<article class="prose prose-h1:text-sky-700">
<%= Phoenix.HTML.raw(Earmark.as_html!(@article)) %>
</article>
"""
end
end
Adding liveviews to the router
Our files are ready, it’s time to hook them in the app’s router. Open up router.ex in lib/my_app_web/ directory, and add two lines in the default scope "/".
live "/blog", BlogLive
live "/blog/:title", ArticleLive
Time to open up the browser and visit:
localhost:4000/blogNow we can see our files in a list:
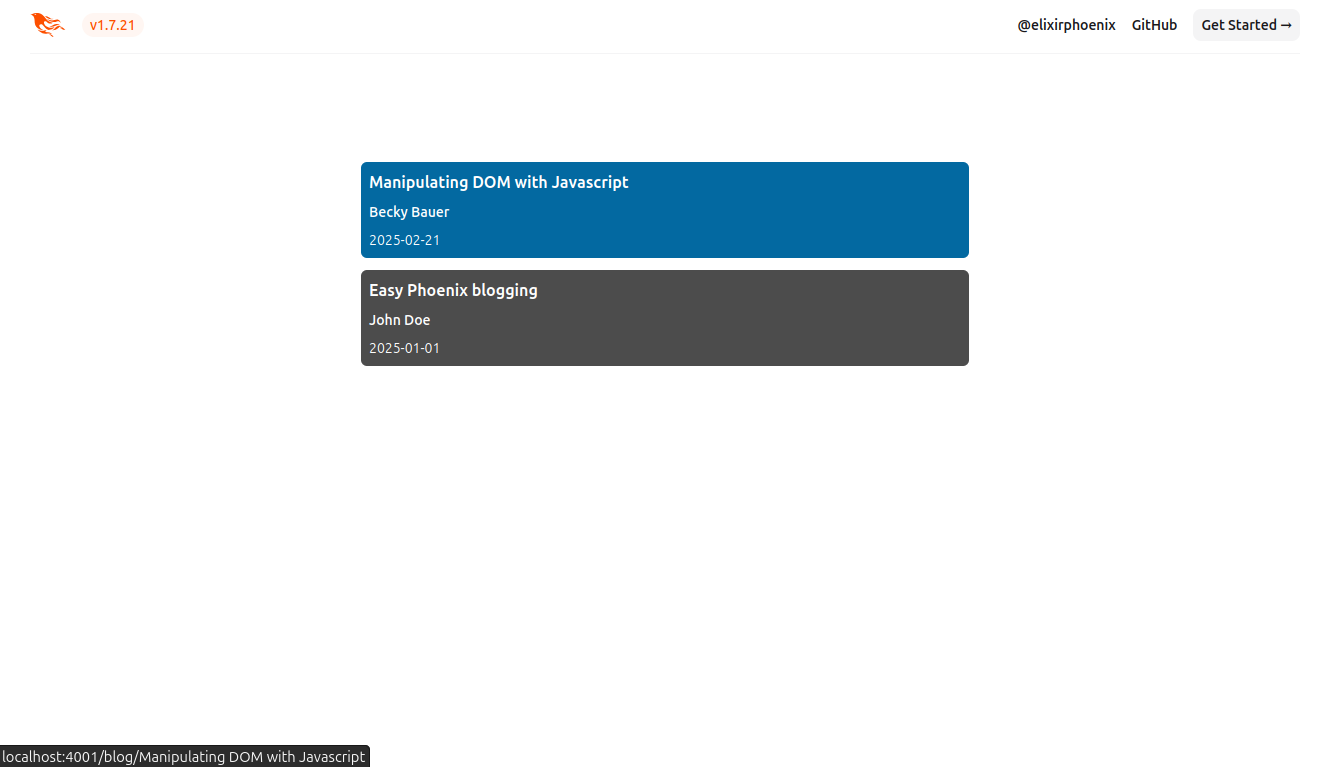
When we click on one of the posts it will open its contents with styles added by tailwindcss-typography plugin:
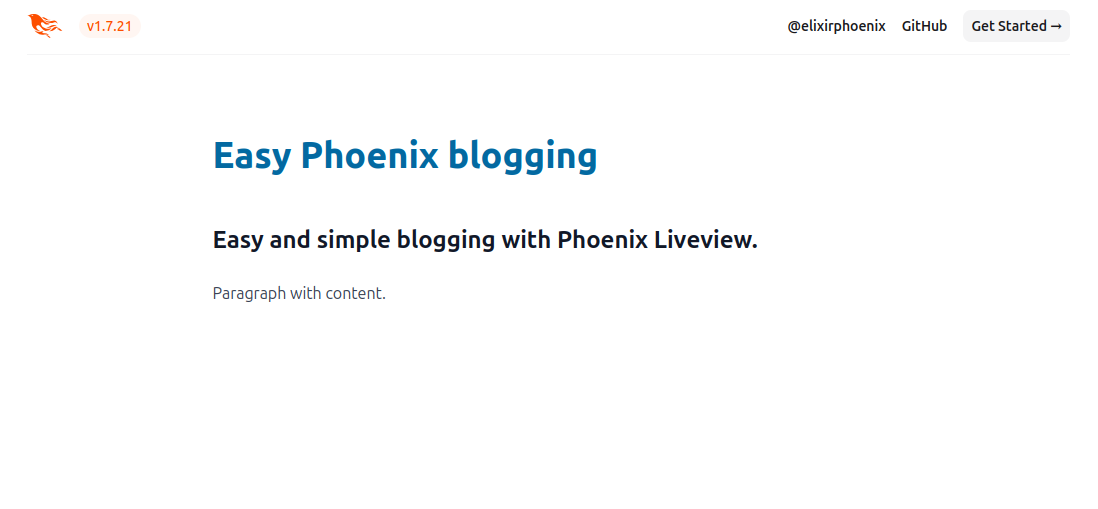
And that’s it, we built a base project for blogging in Phoenix Liveview. We could enhance the list with sorting and filtering or create an oauth app and let visitors leave comments and likes, but that’s a task for a future article.